SQL语法
参考:MySQL必知必会
SQL语法顺序
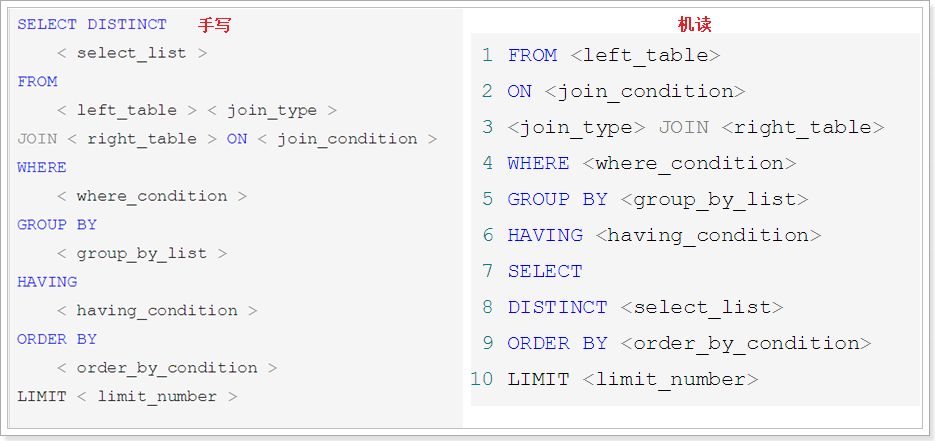
SQL
SELECT
检索数据
SELECT 列 FROM 表名; # 单个列
SELECT 列1,列2,列3 FROM 表名; # 多个列
SELECT * FROM 表名; # 所有列
DISTINCT
去重,只返回选择列唯一的行。
SELECT DISTINCT 列 FROM 表名;
LIMIT
限制结果,只显示前n行。
SELECT 列 FROM 表名 LIMIT 5,5; # 从行5开始的5行
限定名
SELECT 表名.列 FROM 表名 # 限制列名
SELECT 表名.列 FROM 数据库.表名 # 限制表名
ORDER BY
默认升序排列(从A到Z)
SELECT 列 FROM 表名 ORDER BY 列;
SELECT 列1,列2,列3 FROM 表名ORDER BY 列1,列2; # 先按列1排序,然后再按列2排序
DESC
降序排序,从Z到A排序
SELECT 列 FROM 表名 ORDER BY 列 DESC;
WHERE
过滤数据
SELECT 列1,列2 FROM 表名 WHERE 列1 = 2.5 # 从表中检索两个列,只返回列1值等于2.5的行
WHERE子句操作符
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN | 在指定的两个值之间 例:BETWEEN 5 AND 10 |
对字符串操作时需要加单引号
# 空值检查
SELECT 列1,列2 FROM 表名 WHERE 列1 IS NULL; # 返回列1为空(不是为0)
AND
用在WHERE子句中的关键字,用来指示检索满足所有给定条件的行。
OR
OR操作符与AND操作符不同,它指示MySQL检索匹配任一条件的行。
IN
IN操作符用来指定条件范围,功能与OR相当。
SELECT 列1,列2 FROM 表名 WHERE 列1 IN (1002,1003);
NOT
NOT WHERE子句中用来否定后跟条件的关键字。
LIKE
通配符:%表示任何字符出现任意次数,_用途与%一样但下划线只匹配单个字符而不是多个字符。
SELECT 列1,列2 FROM 表名 WHERE 列1 LIKE 'jet%'; # 检索任意以jet起头的词
REGEXP
REGEXP后所跟的东西作为正则表达式
Concat()
把两个列拼接起来
SELECT Concat(列1,'(',列2,')') FROM 表名; # 列1(列2)
AS
起别名
文本处理函数
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Length() | 返回串的长度 |
| Locate() | 找出串的一个子串 |
| Lower() | 将串转换为小写 |
| LTrim() | 去掉串左边的空格 |
| Right() | 返回串右边的字符 |
| RTrim() | 去掉串右边的空格 |
| Soundex() | 返回串的SOUNDEX值 |
| SubString() | 返回子串的字符 |
| Upper() | 将串转换为大写 |
日期和时间处理函数
略。
数值处理函数
| 函数 | 说明 |
|---|---|
| Abs() | 返回一个数的绝对值 |
| Cos() | 返回一个角度的余弦 |
| Exp() | 返回一个数的指数值 |
| Mod() | 返回除操作的余数 |
| Pi() | 返回圆周率 |
| Rand() | 返回一个随机数 |
| Sin() | 返回一个角度的正弦 |
| Sqrt() | 返回一个数的平方根 |
| Tan() | 返回一个角度的正切 |
聚集函数
运行在行组上,计算和返回单个值的函数
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
GROUP BY
根据一个或多个列对结果集进行分组。在分组的列上我们通常配合 COUNT, SUM, AVG等函数一起使用。
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
HAVING
过滤分组
HAVING和WHERE的差别:WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。WHERE过滤行,而HAVING过滤分组。
| ORDER BY | GROUP BY |
|---|---|
| 排序产生的输出 | 分组行。但输出可能不是分组的顺序 |
| 任意列都可以使用(甚至非选择的列也可以使用) | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
子查询
在WHERE子句中使用子查询,应该保证SELECT语句具有与WHERE子句中相同数目的列。通常,子查询将返回单个列并且与单个列匹配,但如果需要也可以使用多个列。
连结表
联结是一种机制,用来在一条SELECT语句中关联表,因此称之为联结。
SELECT 列1,列2,列3 FROM 表1,表2 WHERE 表1.列4 = 表2.列4;
没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。

可视化网站:https://joins.spathon.com/
UNION
组合查询
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数。
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型。
使用UNION ALL,MySQL不取消重复的行。
INSERT 插入数据、UPDATE 更新数据、DELETE 删除数据
CREATE TABLE 创建表
AUTO_INCREMENT,本列每当增加一行时自动增量
ALTER TABLE 更新表、DROP TABLE 删除表、RENAME TABLE 重命名表
CREATE VIEW
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
为什么使用视图?
- 重用SQL语句。
- 简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道它的基本查询细节。
- 使用表的组成部分而不是整个表。
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
CREATE VIEW viewname AS SELECT 列1,列2 FROM 表名 WHERE 列1 = 2.2; # 创建视图
SHOW CREATE VIEW viewname; # 查看创建的视图
DROP VIEW viewname; # 删除视图
存储过程
为什么要使用存储过程?
- 通过把处理封装在容易使用的单元中,简化复杂的操作。
- 简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,只需要更改存储过程的代码。
- 由于不要求反复建立一系列处理步骤,这保证了数据的完整性。
- 提高性能。因为使用存储过程比使用单独的SQL语句要快。
- 存在一些只能用在单个请求中的MySQL元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码。
CREATE PROCEDURE productpricing() # 创建存储过程
BEGIN
SELECT 列1,列2 FROM 表名 WHERE 列1 = 2.2;
END;
# 此存储过程名为productpricing,BEGIN和END语句用来限定存储过程体,过程体本身是一个SELECT语句
CALL productpricing() # 使用存储过程
DROP PROCEDURE productpricing() # 删除存储过程
# 可以使用参数 暂时略
SHOW CREATE PROCEDURE productpricing() # 检查存储过程
游标
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
CREATE PROCEDURE processorders()
BEGIN
DECLARE ordernumbers CURSOR # 游标用DECLARE语句创建
FOR
SELECT order_num FROM orders;
END;
OPEN ordernumbers; # 打开游标
FETCH ordernumbers INTO o; # 检索当前行的order_num列(将自动从第一行开始)到一个名为o的局部声明的变量中。
CLOSE ordernumbers; # 关闭游标
触发器
触发器是MySQL响应以下任意语句而自动执行的一条MySQL语句(或位于BEGIN和END语句之间的一组语句):DELETE、INSERT、UPDATE。只有表才支持触发器,视图不支持,每个表最多支持6个触发器。
CREATE TRIGGER newproduct AFTER INSERT ON products
FOR EACH ROW SELECT 'Product added';
# CREATE TRIGGER 创建触发器
# AFTER INSERT 在INSERT语句成功执行后执行 BEFORE 在之前
# FOR EACH ROW 对每个插入行执行
DROP TRIGGER newproduct # 删除触发器
事务
事务处理(transaction processing)可以用来维护数据库的完整性,它保证成批的MySQL操作要么完全执行,要么完全不执行。
START TRANSACTION; # 事务开始
ROLLBACK; # 回退
COMMIT; # 提交
SAVEPOINT delete1; # 使用保留点
ROLLBACK TO delete1; # 回退到保留点
事务处理用来管理INSERT、UPDATE和DELETE语句。不能回退SELECT语句或CREATE或DROP操作。
插入、更新、删除
INSERT INTO 表名 VALUES(,,);
UPDATE 表名 SET 列名 = ' ' WHERE 过滤条件 # 可以删除某个列的值
DELETE FROM 表名 WHERE 过滤条件 # 删除特定的行
创建表
CREATE TABLE 表名();